Richard Pönighaus, Johann Mitlöhner
Vienna University of
Economics/Department of Applied Computer Science
A-1090 Augasse
2--6, Vienna, Austria
Email: poenigh@wu-wien.ac.at, mitloehn@wu-wien.ac.at
From Proceedings of WebNet 1996 - World Conference of the Web Society San Francisco, California, USA, October 15-19, 1996. AACE 1996
Abstract: In this work we describe an approach to the generation of HTML code based on meta information contained in typical relational database systems. In principle reverse engineering methods can automatically produce web pages from any database without the need for additional user input. Additional information can be supplied in order to improve the structure of the resulting web pages. We successfully applied our approach to several databases from different domains; in this paper, we use a database on classical records and its corresponding meta model to illustrate the method and point out problems which arise in automatic code generation from databases.
With the ever-growing popularity of the World Wide Web people become used to exploring data in new ways. Navigating through hypertexts is becoming more and more common for users in diverse domains of application. The presentation of data in HTML format allows for plattform-independence and easy access for non-technical users.
Recently there has been growing reserach interest in meta-data [Metadata 1996] in diverse areas. Relational databases are capable of storing data in a highly structured way; when attempting to generate hypertexts from database records, the system catalog of the database can provide information on relationships between database tables on the meta-level. On the instance-level this allows for automatic creation of hypertext links between documents.
Among other things, database systems offer the advantage of being able to store large amounts of data in a consistent way. Today, many database applications exist in a variety of application domains. Several reasons exist for making data stored in these applications accessible via the web:
Those points are valid not only for Intranets (within an organization), but also for Internet users distributed all over the world. In the next sections we demonstrate the process of automatic hypertext generation by using the example of a database of classical records.
In our model a piece of music is composed by exactly one composer. Several artists may take part in the recording of a piece, optionally performing in a role specific to the piece (such as singers in opera). The record may be of a part of the piece, or of the whole piece. A CD may contain one or more recordings.
Fig. 1: The ER-diagramms for the records database (a)
and the system catalog (b)
The relevant entities are Composer, Piece, Part, Artist, Role, Recording, CD, and Label; the cardinality of relationships between those entities are one-to-many, except for the many-to-many relationship Performs. The corresponding ER-diagram is shown in [Fig. 1a] (the ER-modelling approach was first introduced by [Chen 1976]).
How can this database be viewed? For a hypertext, we need a starting point. In the example, a good starting point would be a list of composers. Following a link for a specific composer would answer the question `` What are the pieces written by that composer?''. Following the link for a piece would show a list of recodings of that piece. The link of a recording would lead to the CD that contains that recording.
Another starting point would be a list of the artists. Following a link on an entry in that list would answer the question `` What recordings did this artist take part in?''.
In the following sections we will discuss our approach to the automatic generation of HTML code from a relational database. We will draw on examples from the music database described in this section.
When building applications, we must often start from old system, and we often do not exactly know their structure, as has been summarized by [Waters & Chikofsky 1994]:
``... while many of us may dream that the central business of software engineering is creating clearly understood new systems, the central busines is really upgrading poorly understood old systems. By implication, reverse engineering is arguably one of the most important parts of software engineering, rather than being a peripheral concern.''
Relational system are in principle very well suited for reverse engineering. [Markowitz & Makowsky 1990] show a theoretically sound approach but assume good design and full normalization which often does not occur in real applications.
CREATE TABLE Composer CREATE TABLE Piece
(ComposerID INTEGER NOT NULL, (PieceID INTEGER NOT NULL,
Name CHAR(30) NOT NULL, ComposerID CHAR(18),
FirstName CHAR(30), Title CHAR(50) NOT NULL,
Born DATE, PRIMARY KEY (PieceID),
PRIMARY KEY (ComposerID)); FOREIGN KEY by (ComposerID)
REFERENCES Composer
ON DELETE SET NULL);
CREATE UNIQUE INDEX Composer_ix CREATE UNIQUE INDEX Piece_ix
ON Composer (ComposerID ASC ); ON Piece (PieceID ASC);
Data and index definition for the tables Composer and Piece in SQL
Taking a look at the SQL statements in the music database, we instantly see possibibilities of automatic link generation. The table Composer is referenced by the table Piece; obviously, this reference can be used in generating hypertext link. Assuming we translate each table entry into a web page, one can easily imagine how for each piece of music in the database a link can be added to the field ComposerID in table Piece. The SQL statement defines this field as a foreign key which references the table Composer.
Unfortunately, SQL statements for table creation are not normally available in legacy systems. However, the information is not lost: the RDBMS automatically manages the corresponding structure. In the following section we take a look at the way a RDBMS is storing meta-data about applications.
RDBMS store meta information about applications in system catalog tables. The structure of all objects derived from the data definition language (DDL: SQL statements like CREATE TABLE, CREATE INDEX) in the user databases are described in the catalog tables. Sophisticated systems store other information as well, e. g. on permissions, statements embedded in application programs (DML). In [Pönighaus 1995] an analysis on the usage of SQL statements based on catalog data was performed; here we concentrate on DDL. The meta information contained in the catalog tables is accessible via standard SQL statements. [Fig. 1b] shows an ER-model of a simplified system catalog (our meta base).
System catalogs vary somewhat between database systems. In the following we describe relevant parts of our system catalog here; most widely used database systems provide the information needed, although the corresponding tables and fields would be named differently.
Let us take a look at how the SQL statements from the music database application are translated by the RDBMS into system catalog entries. If the database Music has already been created by the user Smith the catalog table Database contains (among others) the following entry:
DBname | Creator ---------------- ... | Music | Smith ...
The creation of a new table results in an entry being added to the catalog table Tables:
Tbname | Type | DBname | Creator ---------------------------------- ... | | | Composer | E | Music | Smith ...
For each columns of the newly created table, an entry is added to the catalog table Columns (for simplicity we omit the creator name in the following):
Colname | Tbname | Colno | Coltype --------------------------------------- ... | | | ComposerID | Composer | 1 | INTEGER Name | Composer | 2 | CHAR FirstName | Composer | 3 | CHAR Born | Composer | 4 | DATE ...
The primary key declaration and the index creation cause the tables Indexes and Keys to contain the following entries:
Ixname | Tbname | Uniquerule ----------------------------------- ... | | Composer_ix | Composer | P ...
Ixname | Colname | Colno | Colseq | Ordering ---------------------------------------------------- ... | | | | Composer_ix | ComposerID | 1 | 1 | A
In the application table Piece the field ComposerID is a foreign key referencing entries in the table Composer. The declaration ``FOREIGN KEY...'' means that the entries in the column ComposerID relate to entries in the Table Composer; the relationship has been given the name ``by''. This relationship name is entered into the catalog table Relationships by the RDBMS:
Tbname | Relname | Reftbname | Colcount | Deleterule ---------------------------------------------------- ... | | | | Piece | by | Composer | 1 | C ...
To keep track of the columns taking part in the reference, entries into the catalog table Foreignkeys are added. In this case, there is only one corresponding row:
Tbname | Relname | Colname | Colno | Colseq ---------------------------------------------- ... | | | | Piece | by | ComposerID | 2 | 1 ...
In the following section we describe how we make use of the catalog data discussed above in the generation of HTML code.
We use the relationships between database tables which can be found in the system catalog of the RDBMS to automatically build a hypertext from a given database. The resulting HTML code can be viewed with a standard web browser.
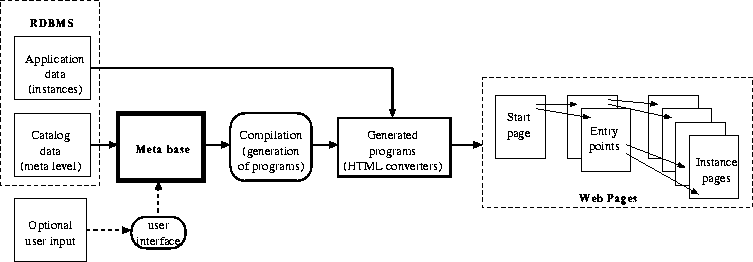
Fig. 2: An overview of the web page generation process
[Fig. 2] shows an overview of our approach. We transfer the data from the system catalog to a meta base; ideally, this data is sufficient for the hypertext generation. However, the user can supply optional additional input in a format consistent with the catalog data. Additional user input allows for increasing the readability of the resulting web pages and for incorporating additional features into the hypertext as explained later.
Our program generator is written in the standard Unix record processing language AWK; the programs generated by our system are in AWK as well. We chose this language for our prototype system since it is very well suited for this type of processing, and it is widely available in commonly used operating system and hardware environments. The meta base is currently implemented in MS ACCESS; additional user input is possible via forms. From the meta base we generate a set of programs. After exporting the application data from the database system those programs create corresponding web pages. Links to other documents, meaningful section titles and formatting commands are added by those programs.
The generated programs are run to produce the web pages from the current application data. A start page is automatically generated to provide a starting point for the data exploration. The resulting web pages form a three-layer hierarchy: the start page, the pages for the different entry points, and the pages for the data instances.
Our hypertext documents are composed of the entries in the database and links to corresponding other entries. In the following, we discuss basic types of documents and special cases.
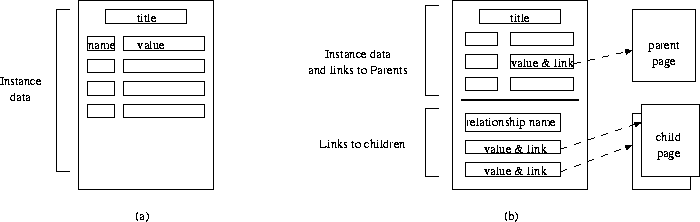
In the simplest case of a table containing no references to other tables and not being referenced by any other table, each entry in the database (a record in a table) is translated into a HTML file containing a title, the names of the fields and their values. A sample document is shown in [Fig. 3a]. If any label text has been supplied in the catalog table Columns or by additional user input, this text is used as the label for a field; otherwise, the column name is used for this purpose.
This more interesting case is depicted in [Fig. 3b] which shows a web page consisting of two parts separated by a rule. Consider a web page for a piece of music: the upper part contains instance data and links to parents. A parent table is a table that is referenced by another table:
the second field in the upper part (ComposerID of table Piece) of Fig. 3b] contains a link that points to a parent (an entry in the table Composer), in this case the composer of the piece. A link to the corresponding web page is provided together with the value (possibly expanded, see sec. 6.2).
The lower part shows a list of children of this piece, i. e. a list of recordings. We use the expanded keys to represent the children. Note that in the case of 1:n-relationsships a parent can have several children.
Fig. 3: A generated stand-alone document (a)
and a document with references (b)
When automatically generating hypertext from database data, we encountered several problems which seem to persist across different application domains. We show those of the problems we have solved in the following sections.
Consider the table Piece: each entry references an entry in the table Composer via the field ComposerID. In many cases this would be a unique number for each composer (an artifical key). In the table Piece this key is contained in the referencing field. Obviously, the resulting web page would not look satisfying, since seeing e. g. the number 42 in the field ComposerID does not tell much; the user would have to follow this link to see what the number stands for.
Substituting the composer's name for the ComposerID would be a substantial improvement here. We saw no way of automatically deducing which fields of a referenced table are meaningful for the reader of the web page. This information has to be supplied by additional user input in the form of additional indexes on tables; existing alternate unique indexes can help the user in this process, since these indexes usually are created on fields that describe an entry in a way meaningful to a human reader. By entering additional indexes for tables the user can provide the HTML generator with information on which fields are ``natural keys'' for that table i. e. the contents of those fields will identify the entry to the user; e. g. in the table Composer, natural keys would be the columns which contain the composer's first and last name. To give this information, the user would enter an additional index of type ``A'' (alternate). The generator uses this information for the key expansion. This information is also used to create more meaningful titles of web pages in the form of <entity name> : <alternate key>.
In complex cases, the key expansion is done in several steps: the meta base table Relationships describes a network of connections between tables in the application which is traversed by the generator using a graph algorithm until it arrives at meaningful contents for hypertext fields.
In the music database, the information on which artists participated in the recording of a piece is stored in a table Performs. This table is an associative entity: it is neccessary for the implementation of the many-to-many relationship: more than one artist can take part in a recording, and each artist can take part in more than one recording in a particular role. However, the table Performs is not interesting in itself; the reader of the hypertext would prefer to perceive the information only in the form of a list added to the Recording page: this list should directly state the artists taking part in the recording plus their role, not the entries in the table Performs that reference this recording. The table Performs should not be part of the hypertext system in the same way that Composer, Piece, Artist, Role and Recording are: we want the information of artist participance in recordings, but we do not want a web page for each entry in the table Performs.
If foreign keys are defined in the application, we can automatically deduce the information of whether an entity is an associative entity and should be omitted: in our prototype no web pages are created for tables that consist only of foreign keys.
Often information on foreign keys is not supplied within the RDBMS; our experience confirms what [Premerlani &Blaha 1994] say: ``Finding candidate keys is easy, finding foreign keys is difficult.''
The declaration of foreign keys is often lacking for reasons of performance, or because legacy RDBMS did not support the corresponding definitions. Additional user input (deriving from knowledge of the application domain) can clarify the situation.
Readability and accessability of our generated hypertexts have been significantly improved by the introduction of groupings and listings which serve as entry points to sets of instance web pages [Fig. 2]. Hierarchical groupings and ordered lists are defined by special index types (indicated in our meta base by ``G'' and ``L'', resp.). These have to input by the user.
During the development of our system, several topics have been postponed to future investigation. They fall into the two areas of formatting and structural improvements:
In this work we show an approach to the automatic generation of hypertext from relational databases using metadata. Reverse engineering applied to relational databases proves to be applicable to this problem, since the referencing information provided by the database system is ideally suited for automatically generating hypertext links between documents for instances of entities. The use of a meta base which is extracted from the system catalog and which can be augmented by the user allows for a flexible solution to the problems typically found in practical database applications. In this text the method is applied to a database on music records. Interested readers are invited to take a look at the music database at http://exaic.wu-wien.ac.at/~poenigh/platten/entry.htm.